



Résilience infrastructure: pourquoi le 3-AZ OVH change la donne pour l'hyperconvergence Ceph
Le modèle 3-AZ OVH permet de bâtir une architecture hyperconvergée plus résiliente, à condition de respecter les exigences de latence et de réseau privé de Ceph.
Quand on parle de résilience, beaucoup d’équipes s’arrêtent au mot “haute disponibilité”.
En pratique, la vraie question est plus concrète: est-ce que l’infrastructure continue à servir quand une zone complète tombe?
C’est exactement l’intérêt d’une architecture pensée autour du 3-AZ OVH et d’une couche data hyperconvergée avec Ceph.
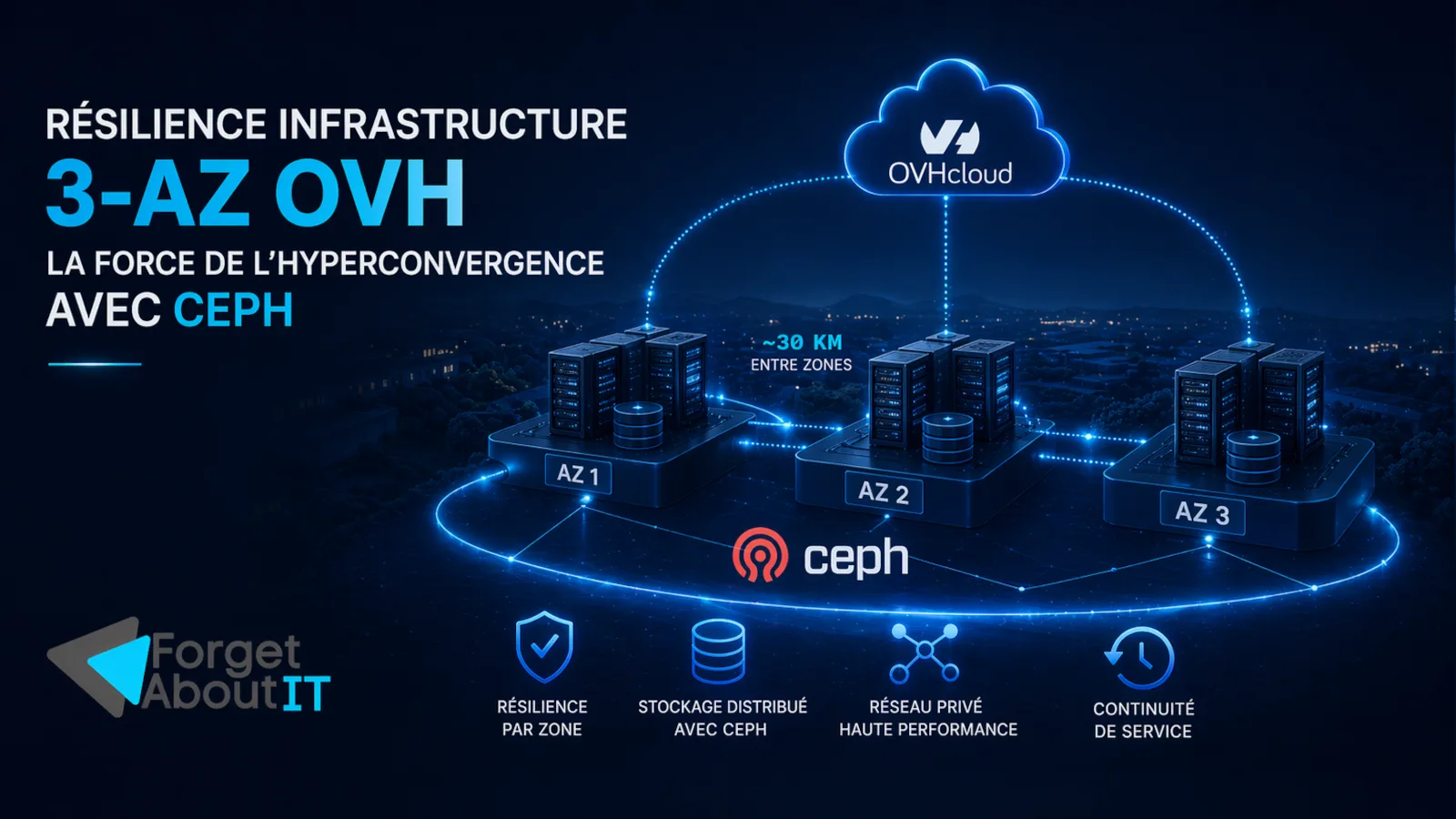
3-AZ OVH: un socle pertinent pour la résilience
OVH positionne sa région Paris 3-AZ autour de trois points clés:
- 3 zones de disponibilité indépendantes;
- environ 30 km entre zones;
- un réseau privé faible latence dédié.
Sur le papier, c’est ce qu’il faut pour construire une architecture tolérante aux incidents majeurs sans multiplier les opérateurs.
La différence avec une logique mono-zone (1-AZ), c’est le niveau de blast radius: quand on distribue vraiment les rôles applicatifs et data, on réduit le risque qu’un incident local devienne un incident global.
Pourquoi c’est particulièrement intéressant pour l’hyperconvergence
Une plateforme hyperconvergée regroupe calcul, stockage et réseau au sein d’un même cluster.
Le bénéfice est connu: plus de cohérence opérationnelle, moins de silos, une exploitation plus simple.
Mais ce modèle impose une discipline stricte sur le réseau:
- le stockage distribué parle en continu entre nœuds;
- les écritures synchrones dépendent de la qualité des échanges inter-nœuds;
- la reconstruction après panne peut générer des pics de trafic importants.
Autrement dit: sans réseau solide, l’hyperconvergence devient vite fragile.
Ceph: faible latence et bande passante ne sont pas “optionnelles”
Les recommandations Ceph sont claires: partir au minimum sur du 10 Gb/s, et viser 25 Gb/s (ou plus) pour les charges soutenues.
C’est cohérent avec le terrain: la réplication, le rebalance et le recovery consomment énormément de réseau.
C’est là que l’écosystème OVH devient intéressant pour ce type de design:
- réseau privé vRack sur serveurs compatibles;
- profils selon gammes avec 25 ou 50 Gbps de capacité privée;
- interconnexion adaptée aux architectures clusterisées.
Le bon raisonnement n’est donc pas “combien de vCPU j’ai”, mais plutôt:
- quel débit utile j’ai en cas de reconstruction;
- quelle latence inter-zones je tiens en charge;
- quelle marge je garde pendant un incident réel.
Design de référence: 3-AZ + Ceph + orchestration de charge
Dans un schéma type orienté continuité de service:
- chaque AZ héberge des nœuds de calcul;
- Ceph répartit les données avec des règles de placement alignées sur les zones;
- les composants critiques applicatifs sont distribués (pas concentrés dans une seule AZ);
- le trafic de réplication est isolé et priorisé sur le réseau privé.
Objectif: conserver un service utilisable même en cas de perte d’une zone, puis revenir rapidement à un état sain sans saturation réseau.
Les erreurs fréquentes à éviter
-
Confondre “3 datacenters” et “architecture résiliente”.
Sans design applicatif et data adapté, 3-AZ ne protège pas automatiquement. -
Sous-dimensionner le réseau privé.
Ceph peut fonctionner, mais dégrader fortement les temps d’écriture et de reconstruction. -
Oublier les scénarios dégradés.
Une architecture doit être validée en charge pendant incident, pas seulement en nominal. -
Ne pas tester régulièrement la reprise.
Sans exercices de panne planifiés, le RTO devient théorique.
Ce que nous faisons en pratique chez Forget About IT
Sur les projets hyperconvergés, on travaille en priorité sur:
- la cartographie des dépendances critiques;
- le placement multi-AZ des composants stateful et stateless;
- le dimensionnement réseau (débit, isolation, marge);
- les tests de perte de nœud/AZ et de reconstruction Ceph;
- le runbook d’exploitation pour garantir une reprise maîtrisée.
Le but n’est pas de “cocher 3-AZ”, mais de livrer une plateforme qui tient quand la situation devient réellement stressante.
Conclusion
Le 3-AZ OVH est un excellent socle pour augmenter la résilience d’une infrastructure.
Mais la valeur réelle apparaît quand il est combiné avec une architecture hyperconvergée correctement conçue, surtout sur la couche Ceph.
Si le réseau privé, la latence et les mécanismes de reprise sont traités dès la conception, on obtient une plateforme plus robuste, plus prévisible, et réellement exploitable en production.
- Découvrir notre approche de l’hyperconvergence
- Voir notre accompagnement OVH
- Parler de votre architecture avec nous
Sources
- OVHcloud — Résilience et AZ (région 3-AZ Paris)
- OVHcloud — Régions et Availability Zones
- OVHcloud — Gammes bare metal (réseau privé 25/50 Gbps selon offres)
- Ceph Documentation — Hardware recommendations (réseau et performance)
FAQ: résilience 3-AZ OVH et hyperconvergence Ceph
Pourquoi 3-AZ est plus résilient qu’une architecture 1-AZ ?
Parce que la charge est répartie sur trois zones indépendantes: la panne d’une zone n’entraîne pas l’indisponibilité globale si l’architecture applicative et data est bien conçue.
Le 3-AZ OVH suffit-il à rendre Ceph hautement disponible ?
Le 3-AZ fournit un excellent socle, mais la disponibilité dépend aussi du design Ceph (réplication, placement, quorum), de la latence inter-zones et des mécanismes de reprise côté applicatif.
Pourquoi la latence est-elle critique pour Ceph ?
Parce que Ceph réplique en continu et échange de nombreux messages de coordination. Une latence instable augmente le temps d’écriture et ralentit les reconstructions après incident.
À quoi correspondent les 25/50 Gbps évoqués chez OVH ?
Sur les gammes compatibles, OVH propose selon les offres un réseau privé vRack à 25 ou 50 Gbps. Ce débit est clé pour absorber la réplication Ceph et les phases de recovery.
Faut-il tout étirer sur 3 AZ avec Ceph ?
Pas systématiquement. On adapte selon le RPO/RTO, la volumétrie et le budget. Certaines architectures mixtes (données synchrones + sauvegardes/DR) sont plus pertinentes.
Articles recommandés

Infrastructure
Maintenance serveur sans interruption: comment l'hyperconvergence évite le downtime
Patch système, mise à jour d'hyperviseur, remplacement matériel: une architecture hyperconvergée bien conçue permet de maintenir les services pendant la maintenance.
Infrastructure
PRA informatique: définir RTO et RPO pour une reprise réellement indépendante
Un PRA utile ne se limite pas à une sauvegarde. Il fixe un RTO, un RPO et une infrastructure de secours réellement séparée du réseau et du provider principal.

Infrastructure
Astreinte externalisée: quand la PME ne peut pas porter du 24/7 en interne
L'astreinte 24/7 ne se résume pas à décrocher un téléphone la nuit. Pour une PME, il faut mesurer le coût réel, la fatigue des équipes, les procédures, les GTI/GTR et l'escalade.