



PRA informatique: définir RTO et RPO pour une reprise réellement indépendante
Un PRA utile ne se limite pas à une sauvegarde. Il fixe un RTO, un RPO et une infrastructure de secours réellement séparée du réseau et du provider principal.
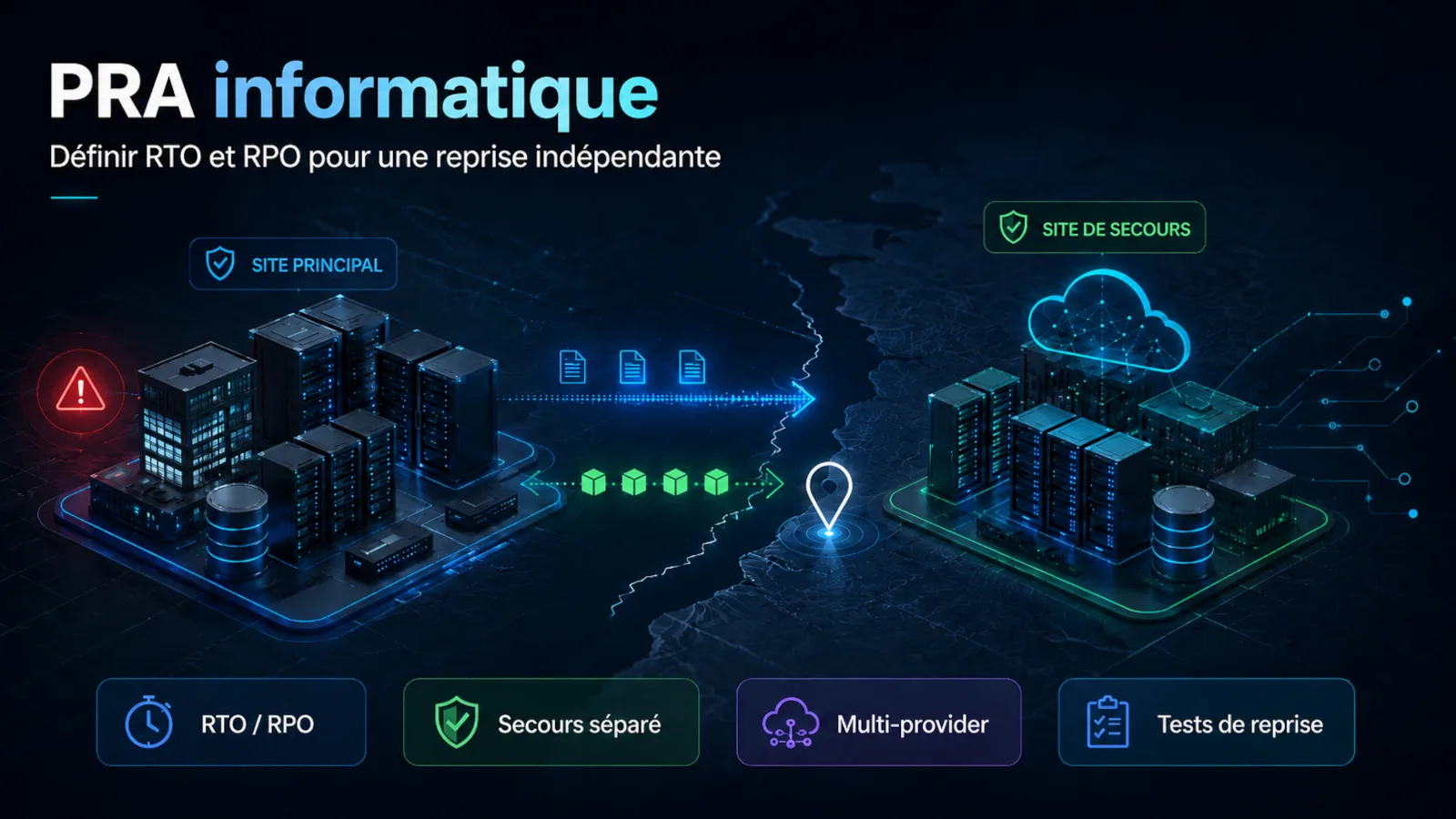
Un serveur tombe, une baie n’est plus alimentée, un opérateur réseau connaît un incident majeur ou un compte d’administration devient indisponible. Dans ces situations, disposer de sauvegardes est indispensable. Mais cela ne répond qu’à une partie du problème.
Le vrai sujet est le suivant: dans quel délai l’activité peut-elle reprendre, avec quelle perte de données, sur quelle infrastructure et avec quels accès? C’est précisément le rôle du plan de reprise d’activité, ou PRA.
Un PRA crédible ne tient pas dans une ligne de contrat ni dans la présence d’une copie distante. Il repose sur des objectifs explicites, une infrastructure de secours suffisamment indépendante et des procédures réellement testées.
PRA, PCA, haute disponibilité et sauvegarde: des rôles différents
Ces mécanismes contribuent tous à la résilience, mais ils ne couvrent pas les mêmes incidents.
- La haute disponibilité absorbe certaines pannes locales, par exemple la perte d’un hôte dans un cluster.
- Le PCA, ou plan de continuité d’activité, vise à maintenir le service pendant l’incident.
- Le PRA organise le redémarrage après une interruption majeure.
- La sauvegarde conserve des points de restauration exploitables en cas de suppression, corruption, chiffrement ou perte de l’environnement principal.
Une plateforme virtualisée redondée n’est donc pas automatiquement un PRA. Si tous les nœuds dépendent du même site, du même réseau, de la même alimentation ou du même plan de contrôle, un incident commun peut rendre toute la plateforme indisponible.
De la même manière, une sauvegarde hors site n’est pas une reprise d’activité complète. Il faut encore disposer de capacité de calcul, reconstruire le réseau, restaurer les données, redémarrer les applications dans le bon ordre, rétablir les flux et valider le service.
RTO et RPO: traduire le risque en objectifs mesurables
Un PRA commence par deux indicateurs: le RTO et le RPO. Ils doivent être définis par service, à partir des conséquences métier d’une interruption.
RTO: combien de temps pour reprendre?
Le Recovery Time Objective correspond à la durée maximale visée pour rétablir un service après l’incident.
Un RTO de quatre heures ne signifie pas simplement que la restauration des données doit durer moins de quatre heures. Le chronomètre inclut notamment:
- la détection et la qualification de l’incident;
- la décision de déclencher le PRA;
- l’accès aux consoles et aux secrets nécessaires;
- le démarrage ou le provisionnement de l’infrastructure de secours;
- la restauration des données;
- le redémarrage ordonné des services;
- la bascule DNS, réseau ou applicative;
- les contrôles techniques et la validation métier.
Un RTO ambitieux implique généralement davantage de ressources préprovisionnées, d’automatisation et de réplication. Il coûte aussi plus cher à maintenir et à tester. L’objectif doit donc refléter une contrainte métier réelle, pas une valeur choisie par défaut.
RPO: combien de données peut-on perdre?
Le Recovery Point Objective représente la perte de données maximale acceptable, exprimée en temps.
Avec un point récupérable toutes les quatre heures, la perte potentielle peut approcher quatre heures. Pour une application de gestion interne, cela peut parfois être acceptable. Pour des commandes, des transactions ou des données de production, ce sera souvent trop long.
Réduire le RPO demande d’augmenter la fréquence des sauvegardes ou de mettre en place une réplication adaptée. Mais une réplication seule ne protège pas de tout: une suppression, une corruption ou un chiffrement peut également être répliqué. Les copies isolées, historisées et si possible immuables restent nécessaires.
Un objectif par service, pas un chiffre pour toute l’entreprise
Un site e-commerce, un ERP, une messagerie et une plateforme d’archivage n’ont pas la même criticité. Leur attribuer un RTO et un RPO uniques conduit soit à surdimensionner le PRA, soit à protéger insuffisamment les services vitaux.
Le cadrage doit identifier:
- les processus métier réellement critiques;
- les applications et données dont ils dépendent;
- l’ordre de redémarrage;
- les dépendances externes;
- le niveau de service minimal acceptable pendant la reprise.
Cette cartographie permet de concentrer l’investissement là où une interruption aurait le plus d’impact.
Le PRA doit sortir du domaine de panne principal
Le principe central est simple: la plateforme de reprise ne doit pas disparaître avec la plateforme qu’elle est censée remplacer.
Installer le secours dans une autre salle du même bâtiment peut couvrir une panne de serveur, mais pas un incendie, une coupure électrique générale ou la perte des arrivées opérateur. Utiliser une autre zone d’un même provider améliore la situation, sans nécessairement supprimer les dépendances au compte client, au plan de contrôle, au réseau global ou au contrat principal.
La séparation doit être examinée sur plusieurs plans.
Une séparation géographique cohérente
Le site de secours doit être assez éloigné pour ne pas subir le même événement physique: inondation, incendie, coupure de fibre, panne électrique régionale ou difficulté d’accès au site.
La distance n’est toutefois pas un objectif en soi. Elle influence la latence, le débit de réplication, le temps de transfert des sauvegardes et parfois la localisation juridique des données. Le bon choix équilibre indépendance géographique, performance, capacité de restauration et exigences de souveraineté.
Des réseaux et des accès indépendants
Un PRA hébergé ailleurs mais administré uniquement à travers le réseau principal reste fragile. Il faut vérifier l’indépendance des éléments nécessaires au déclenchement:
- accès administrateur et bastion;
- annuaire, MFA et coffre de secrets;
- DNS et gestion des domaines;
- routage, VPN et opérateurs télécoms;
- supervision et canaux d’alerte;
- dépôts de sauvegarde et catalogues de restauration.
Les identifiants de secours doivent être disponibles sans dépendre d’un service déjà indisponible, tout en restant protégés et tracés.
Des dépendances physiques et contractuelles connues
Deux logos cloud ne garantissent pas deux domaines de panne. Des providers distincts peuvent partager un opérateur, une route fibre, une zone d’interconnexion, un sous-traitant ou une dépendance logicielle commune.
Le multicloud n’apporte de résilience que si les dépendances réelles sont identifiées. Cela suppose de documenter la localisation des données, les chemins réseau, les responsabilités de chaque acteur, les conditions d’accès et la capacité effective à restaurer hors du périmètre touché.
Changer de provider pour le secours ajoute aussi de la complexité: formats, APIs, réseau, compétences et procédures diffèrent. Cette diversité doit être maîtrisée par l’automatisation, la documentation et des tests réguliers.
Secours froid, tiède ou chaud: choisir selon le RTO
Toutes les entreprises n’ont pas besoin d’une plateforme active en permanence. Trois modèles permettent d’ajuster le dispositif au niveau de criticité.
Le secours froid
L’infrastructure est reconstruite ou activée après l’incident, puis les données sont restaurées. Ce modèle limite les ressources permanentes, mais demande davantage de temps. Il convient aux services dont le RTO se compte en heures ou en jours, sous réserve que les scripts, images, licences et capacités nécessaires soient réellement disponibles.
Le secours tiède
Une partie de la cible est préprovisionnée: réseau, stockage, socle de virtualisation ou machines essentielles. Les données sont synchronisées ou restaurées au déclenchement. Le délai de reprise diminue sans maintenir un double complet de la production.
Le secours chaud
La plateforme de reprise est prête à recevoir le trafic, voire déjà active. Elle peut viser un RTO très court, mais demande une architecture plus complexe, une surveillance continue et des tests de bascule rigoureux. Elle ne dispense pas des sauvegardes isolées.
Le modèle peut varier au sein d’un même PRA. Les briques critiques démarrent sur un secours chaud ou tiède, tandis que les services secondaires sont restaurés plus tard.
Une cible multi-provider, dont Castle IT
FAIT conçoit et opère des PRA auprès de différents providers, en fonction de l’existant, des contraintes de localisation et du niveau d’indépendance recherché. La cible peut notamment s’appuyer sur OVHcloud, Scaleway, IONOS ou Castle IT. Le choix n’est pas une collection de fournisseurs: il doit supprimer des dépendances précises et rester exploitable le jour de l’incident.
Castle IT constitue par exemple une option française pour décorréler une infrastructure principale hébergée chez un autre opérateur. Son datacenter principal est situé à Larçay, près de Tours. L’environnement permet d’envisager une infrastructure dédiée ou virtualisée, hébergée en France, avec des serveurs dédiés assemblés en France et une possibilité d’intervention physique sur site.
Dans ce cadre, le partage des responsabilités reste lisible: Castle IT fournit l’environnement d’hébergement et les ressources physiques; FAIT prend en charge la conception, l’exploitation, les sauvegardes, les procédures de reprise et la coordination technique. Une capacité peut être préprovisionnée afin de réduire le temps nécessaire à la restauration ou à la bascule.
Cette approche ne consiste pas à remplacer un logo cloud par un autre. Elle vise à obtenir:
- une localisation connue des données critiques;
- une infrastructure de reprise hors du périmètre principal;
- des sauvegardes restaurables sur la cible retenue;
- des responsabilités et des procédures documentées;
- une intervention coordonnée en cas d’incident;
- des preuves issues de tests réels.
Pour les environnements concernés par des contraintes de conformité, le cadrage Castle IT s’appuie également sur ses référentiels ISO 27001:2022 et HDS v2. Ces certifications ne remplacent pas l’analyse d’architecture: le périmètre exact, les responsabilités et les mesures opérationnelles doivent toujours être vérifiés pour chaque projet.
Notre page consacrée à l’infogérance Castle IT détaille cette articulation entre hébergement, exploitation et accompagnement.
Tester la reprise, pas seulement la procédure
Un document à jour est utile, mais il ne prouve pas qu’un service redémarrera dans le délai annoncé. Un PRA non testé reste une intention. Le test transforme cette intention en mesure vérifiable.
Un exercice complet doit permettre de répondre à des questions concrètes:
- les sauvegardes sont-elles lisibles et restaurables hors de la production?
- les volumes de données sont-ils compatibles avec le RTO?
- les accès de secours fonctionnent-ils sans l’annuaire principal?
- les applications redémarrent-elles dans le bon ordre?
- les règles réseau, certificats et secrets sont-ils disponibles?
- la bascule DNS ou réseau est-elle maîtrisée?
- qui décide, qui exécute et qui valide le retour du service?
Le test doit mesurer les temps réels, relever les écarts et produire un compte rendu. Il révèle souvent les dépendances oubliées: licence liée à une adresse IP, dépôt de paquets inaccessible, certificat absent, bande passante insuffisante ou procédure qui repose sur une seule personne.
Tous les exercices n’ont pas besoin d’interrompre la production. Des restaurations isolées et des tests partiels peuvent être réalisés régulièrement. Une bascule complète reste toutefois nécessaire à intervalles définis et après une évolution majeure de l’architecture.
Exploiter le PRA dans la durée
Le PRA n’est pas un projet que l’on termine puis que l’on archive. Chaque changement de version, nouvelle dépendance, évolution réseau ou augmentation du volume de données peut modifier le RTO réel.
Son exploitation doit donc inclure:
- le contrôle des sauvegardes et des réplications;
- la surveillance du retard de réplication;
- la vérification des capacités disponibles sur le site de secours;
- la mise à jour des procédures et des contacts;
- la rotation contrôlée des secrets;
- des restaurations régulières;
- des exercices de reprise avec suivi des actions correctives.
La sortie de crise doit aussi être prévue. Une fois le service relancé sur le site de secours, il faut décider comment revenir vers une plateforme nominale, resynchroniser les données et éviter une nouvelle interruption.
Construire un PRA défendable
Un PRA solide ne promet pas une disponibilité abstraite. Il permet d’expliquer, preuves à l’appui, quels services reprendront, dans quel ordre, avec quelle perte de données et sous la responsabilité de qui.
Le point de départ n’est donc pas le choix d’un provider ou d’un outil. Il s’agit d’abord de fixer les RTO et RPO métier, puis de cartographier les dépendances et les domaines de panne. L’architecture de secours vient ensuite, avec un niveau de préprovisionnement cohérent et une séparation géographique, réseau et administrative suffisante.
FAIT accompagne ce travail de bout en bout: cadrage, architecture multi-provider, automatisation, sauvegardes, documentation, exploitation et tests de reprise.
Cadrer votre PRA avec un ingénieur
Questions fréquentes sur le PRA
Qu’est-ce qu’un PRA informatique?
Un plan de reprise d’activité organise le redémarrage des services informatiques après un incident majeur. Il précise les priorités, les responsabilités, les moyens techniques, les procédures et les délais attendus.
Quelle est la différence entre RTO et RPO?
Le RTO fixe la durée maximale visée pour rétablir un service. Le RPO fixe la quantité maximale de données que l’entreprise accepte de perdre, exprimée en durée depuis le dernier point récupérable.
Une sauvegarde suffit-elle à constituer un PRA?
Non. Une sauvegarde protège des données, tandis qu’un PRA prévoit aussi une infrastructure de secours, les accès, le réseau, l’ordre de redémarrage, les procédures et les tests de restauration.
Pourquoi placer le PRA chez un autre provider?
Un autre provider peut réduire les dépendances communes au site principal: réseau, alimentation, contrôle d’accès, compte client ou zone géographique. Cette séparation doit toutefois être vérifiée techniquement et contractuellement.
À quelle fréquence faut-il tester un PRA?
La fréquence dépend de la criticité et du rythme des changements. Un test doit au minimum être rejoué après une évolution majeure et selon un calendrier régulier, avec mesure des délais et compte rendu.
FAIT peut-il opérer un PRA auprès de plusieurs providers?
Oui. FAIT conçoit et opère des architectures de reprise chez différents providers, en adaptant la cible aux contraintes de l’infrastructure principale, aux objectifs RTO et RPO et aux exigences de localisation.
Articles recommandés

Infrastructure
Astreinte externalisée: quand la PME ne peut pas porter du 24/7 en interne
L'astreinte 24/7 ne se résume pas à décrocher un téléphone la nuit. Pour une PME, il faut mesurer le coût réel, la fatigue des équipes, les procédures, les GTI/GTR et l'escalade.

Infrastructure
Serveurs dédiés OVH: comparatif des gammes Rise, Advance et Scale
Rise, Advance ou Scale: quelle gamme de serveurs dédiés OVH choisir selon votre usage, du lab interne à la production sensible en haute disponibilité.

Infrastructure
Proxmox VE 9.2: nouveautés, Dynamic Load Balancer et clusters HA
Proxmox VE 9.2 introduit un Dynamic Load Balancer, renforce le SDN et simplifie plusieurs opérations de maintenance sur les clusters HA.