



L'IA en cybersécurité: remède et accélérateur de crise
L'IA accélère la découverte de vulnérabilités, mais elle accélère aussi le bruit, les doublons, l'exploitation et la charge de remédiation pour les équipes.

L’intelligence artificielle est en train de modifier le rythme de la cybersécurité.
Pas seulement parce qu’elle aide à écrire du code, analyser des logs ou résumer des rapports. Elle change surtout le volume et la vitesse de découverte des vulnérabilités. Des failles qui seraient peut-être restées discrètes plus longtemps remontent désormais plus vite, parfois en série, parfois avec des doublons, parfois avec une qualité très variable.
Le sujet est donc moins simple que “l’IA protège” ou “l’IA menace”.
L’IA devient à la fois un remède et un accélérateur de crise. Elle permet aux défenseurs de voir plus tôt. Elle permet aussi aux attaquants de chercher plus vite. Entre les deux, les équipes d’exploitation, de sécurité et de maintenance doivent absorber plus d’alertes, plus de correctifs, plus de décisions, plus souvent.
Une nouvelle vague de vulnérabilités assistées par IA
VulnCheck observe déjà une hausse marquée du volume de CVE chez plusieurs fournisseurs et projets open source depuis le début de l’année 2026. Son analyse cite notamment des augmentations fortes chez Chrome, VMware, Apache, Mozilla, HPE, F5 et GitHub. Le rapport reste prudent: toute hausse de CVE ne peut pas être attribuée mécaniquement à l’IA. Mais le signal est suffisamment net pour poser la question d’un changement de régime.
Ce qui change, ce n’est pas seulement qu’un modèle peut trouver un bug. C’est qu’il peut être utilisé à grande échelle:
- lecture rapide de bases de code volumineuses;
- comparaison entre versions;
- recherche de motifs dangereux;
- génération de cas de test;
- aide à la reproduction;
- tri préliminaire de comportements suspects;
- rédaction de rapports plus ou moins structurés.
Pour les éditeurs, les équipes PSIRT, les mainteneurs open source et les chercheurs, c’est une opportunité réelle. Des vulnérabilités latentes peuvent être repérées plus tôt. Des familles de bugs peuvent être inspectées plus largement. Des correctifs peuvent être proposés plus vite.
Mais cette même accélération produit un effet secondaire: le système de triage devient lui-même une cible de surcharge.
Le même outil sert les deux camps
La cybersécurité a toujours vécu avec cette symétrie: une information utile aux défenseurs peut aussi être utile aux attaquants.
L’IA renforce cette symétrie.
Un défenseur peut demander à un modèle d’expliquer un chemin de code, de repérer une hypothèse fragile ou de proposer un test de non-régression. Un attaquant peut utiliser des capacités proches pour comprendre un logiciel, automatiser une partie de la reconnaissance, accélérer la mise au point d’un exploit ou identifier des cibles exposées.
Google Threat Intelligence Group a documenté cette bascule: les adversaires utilisent déjà l’IA pour la recherche de vulnérabilités, l’aide à l’exploitation, l’obfuscation, la reconnaissance et certains workflows plus autonomes. Le point important n’est pas que chaque attaquant dispose soudain d’un outil magique. Le point important est que l’IA réduit le coût de certaines étapes longues, répétitives ou très documentaires.
Pour les défenseurs, cela impose une lecture froide: si l’IA permet de trouver davantage de failles, il faut partir du principe que les failles intéressantes seront aussi découvertes plus vite par des acteurs moins bienveillants.
La fenêtre entre “faille identifiable” et “faille exploitée” peut donc se contracter.
Plus de découvertes ne veut pas dire moins de crise
Intuitivement, découvrir plus de vulnérabilités semble positif. Et dans l’absolu, ça l’est: une faille connue peut être corrigée.
Mais une vulnérabilité connue crée immédiatement une chaîne de travail:
- comprendre le rapport;
- vérifier s’il est réel;
- déterminer les versions concernées;
- mesurer l’exploitabilité;
- identifier les systèmes exposés;
- trouver ou produire un correctif;
- tester la correction;
- déployer;
- redémarrer si nécessaire;
- vérifier que la remédiation est effective.
Quand le volume augmente, cette chaîne ne disparaît pas. Elle s’empile.
C’est particulièrement visible sur Linux et l’open source. Le problème n’est pas seulement d’avoir plus de bugs à corriger. C’est d’avoir plus de rapports à lire, plus de doublons à détecter, plus de faux positifs à écarter, plus de discussions à rediriger et plus de mainteneurs sollicités sur les mêmes sujets.
Le signal d’alerte envoyé par le noyau Linux
Le noyau Linux illustre très bien cette tension.
Dans l’annonce de Linux 7.1-rc4 du 17 mai 2026, Linus Torvalds a signalé que le flux continu de rapports liés à l’IA rendait la liste sécurité presque ingérable, avec une forte duplication: plusieurs personnes trouvent les mêmes problèmes avec les mêmes outils, puis les remontent séparément.
La documentation officielle du noyau a donc clarifié une règle importante: lorsqu’un bug a été identifié avec une assistance IA, il doit être traité comme public, parce que l’expérience de l’équipe sécurité montre que ce type de bug remonte souvent simultanément chez plusieurs chercheurs. La documentation demande aussi de ne pas publier un reproducer dangereux, mais d’indiquer qu’il existe et de le transmettre en privé si les mainteneurs en ont besoin.
Cette règle dit quelque chose de profond: avec l’IA, certaines découvertes cessent d’être rares. Si dix chercheurs utilisent des outils proches sur le même code, ils peuvent trouver les mêmes anomalies presque en même temps.
Le canal privé, conçu pour coordonner des vulnérabilités sensibles, devient alors un entonnoir saturé par des rapports redondants. Et pendant que les mainteneurs trient le bruit, ils passent moins de temps sur les failles réellement urgentes.
La crise n’est pas seulement technique: elle est organisationnelle
L’IA ne fait pas qu’accélérer la découverte. Elle déplace le goulot d’étranglement.
Avant, le frein principal était souvent la capacité à trouver. Demain, le frein principal sera de plus en plus la capacité à qualifier, prioriser et corriger.
Pour une équipe de défense, la question devient:
- quels rapports sont crédibles;
- quels rapports sont des doublons;
- quels rapports concernent une version déjà corrigée;
- quels bugs traversent réellement une frontière de sécurité;
- quelles failles ont un exploit public ou probable;
- quels systèmes internes sont concernés;
- quel patch peut être appliqué sans casser la production;
- quelle mitigation temporaire réduit le risque en attendant.
C’est une usure très concrète. Les équipes ne manquent pas seulement d’alertes. Elles manquent de temps stable pour les transformer en actions fiables.
Le danger est de confondre vitesse de découverte et vitesse de protection. Entre les deux, il y a le travail humain et opérationnel.
Les failles récentes montrent le rythme à absorber
Sur notre propre veille, plusieurs sujets récents illustrent cette accélération de la charge.
Les failles Linux locales comme Copy Fail, DirtyFrag et Fragnesia montrent qu’un même voisinage technique peut générer plusieurs alertes rapprochées: page cache, chemins optimisés du noyau, XFRM/ESP, rxrpc, élévation locale vers root.
Une équipe ne peut pas traiter chaque publication comme un événement isolé. Elle doit comprendre la famille de risque, suivre les bulletins distribution, vérifier les mitigations précédentes, puis confirmer que le noyau corrigé est réellement chargé après redémarrage.
Même logique sur les couches applicatives et d’exploitation. La série de vulnérabilités n8n rappelle qu’un outil self-hosted d’automatisation peut concentrer des credentials, des webhooks, des bases de données et des workflows métier. La faille Nginx Rift rappelle qu’un reverse proxy exposé demande une qualification rapide, mais pas aveugle: version réelle, configuration effective, règles rewrite, exposition Internet.
Ce sont des exemples différents, mais le sujet de fond est le même: la sécurité moderne est devenue une discipline de rythme.
Patcher plus souvent, y compris hors des équipes produit
Quand on parle de vulnérabilités, on pense souvent aux éditeurs: ceux qui développent le produit doivent corriger.
Mais l’augmentation du rythme touche aussi les exploitants, les hébergeurs, les MSP, les équipes IT internes et les responsables de plateformes.
Même si vous ne développez pas NGINX, Linux, n8n ou une dépendance critique, vous devez:
- savoir que la faille existe;
- savoir si votre parc est concerné;
- comprendre si une mitigation est compatible avec vos usages;
- appliquer les paquets corrigés;
- redémarrer les services ou les noyaux quand il le faut;
- vérifier que la version active est bien corrigée;
- documenter l’intervention;
- surveiller les effets de bord.
Cette charge augmente mécaniquement avec le nombre de vulnérabilités publiées.
Le vrai sujet devient donc le maintien en condition de sécurité au quotidien. Une organisation qui patche “quand elle y pense” aura de plus en plus de mal à tenir. Il faut de l’inventaire, de l’observabilité, des procédures de maintenance, des fenêtres de changement, des plans de rollback, des tests de restauration et une veille CVE suivie.
Notre article sur le suivi quotidien des CVE posait déjà ce principe: une vulnérabilité publique est suivie par les défenseurs, mais aussi par les attaquants. L’IA rend ce principe encore plus dur. Elle augmente le nombre de signaux et réduit la tolérance aux retards.
Le piège du tout-automatique
Face à une vague alimentée par l’IA, la tentation est logique: répondre par encore plus d’IA.
Il y a de bons usages:
- regrouper des rapports proches;
- extraire les versions affectées;
- comparer une alerte à un inventaire;
- résumer un avis fournisseur;
- aider à produire une note de changement;
- générer des tests de non-régression;
- proposer une première qualification.
Mais l’automatisation ne doit pas devenir une délégation aveugle.
Un rapport de vulnérabilité utile doit contenir du contexte, une preuve, une reproduction maîtrisée, une analyse d’impact, parfois un correctif. Un patch utile doit être relu, testé et compatible avec les usages réels. Une mitigation utile doit réduire le risque sans créer une panne plus grave.
L’IA peut aider à préparer ce travail. Elle ne remplace pas la responsabilité technique.
Ce que les organisations doivent renforcer maintenant
La réponse stratégique n’est pas d’interdire l’IA ni de tout attendre d’elle.
Il faut renforcer les fondamentaux qui permettent d’absorber une hausse de volume:
- inventaire fiable: versions, services exposés, images conteneurs, dépendances, systèmes critiques;
- veille qualifiée: CVE, bulletins fournisseurs, distributions Linux, exploitabilité réelle, KEV, PoC publics;
- priorisation: exposition Internet, criticité métier, présence d’exploit, complexité de remédiation;
- maintenance régulière: patchs système, applicatifs, noyaux, redémarrages planifiés, tests post-intervention;
- mitigations documentées: mesures temporaires, conditions de retour arrière, impacts connus;
- observabilité: logs, métriques, alertes, comportements anormaux après patch ou tentative d’exploitation;
- discipline de reporting: éviter les rapports bruts, vérifier les doublons, apporter une analyse et, si possible, un correctif.
Dans ce contexte, la maturité ne se mesure pas au nombre d’alertes reçues. Elle se mesure à la capacité de transformer les bonnes alertes en décisions rapides et propres.
Conclusion
L’IA va probablement faire remonter davantage de vulnérabilités. Certaines seront utiles, parfois critiques. D’autres seront des doublons, des rapports incomplets ou des bugs ordinaires mal qualifiés.
Pour les défenseurs, c’est une chance et une contrainte. Une chance, parce que des failles latentes peuvent être corrigées plus tôt. Une contrainte, parce que le volume peut user les équipes, saturer les mainteneurs et rendre la priorisation plus difficile.
Pour les attaquants, c’est aussi un accélérateur. Ils n’ont pas besoin que l’IA soit parfaite. Il suffit qu’elle réduise le coût de la reconnaissance, de l’analyse ou de la mise au point d’un exploit.
La bonne posture consiste donc à rester proche de l’information: suivre les signaux, comprendre les familles de failles, distinguer l’urgence réelle du bruit, patcher plus régulièrement et adapter les procédures au nouveau rythme.
Dans cette phase, l’avantage ne reviendra pas aux organisations qui reçoivent le plus d’alertes. Il reviendra à celles qui savent encore décider clairement quand tout accélère.
Sources
- VulnCheck - The First CVE Wave: Signs That AI-Assisted Vulnerability Discovery Is Reshaping Disclosure Volumes
- LWN - Linux 7.1-rc4, annonce de Linus Torvalds du 17 mai 2026
- Documentation du noyau Linux - Security bugs
- Google Threat Intelligence Group - Adversaries Leverage AI for Vulnerability Exploitation, Augmented Operations, and Initial Access
FAQ: IA et cybersécurité
L’IA améliore-t-elle réellement la cybersécurité ?
Oui, elle peut aider à trouver, qualifier et corriger des vulnérabilités plus vite. Mais elle augmente aussi le volume de signalements, les doublons et la pression sur les équipes qui doivent trier et patcher.
Pourquoi l’IA peut-elle aussi avantager les attaquants ?
Les mêmes capacités qui aident les défenseurs à lire du code, repérer des chemins fragiles ou générer des tests peuvent aider des attaquants à accélérer la recherche de failles, l’écriture d’exploits et la reconnaissance.
Quel est le principal risque pour les équipes de défense ?
Le risque n’est pas seulement technique. C’est l’usure opérationnelle: trop d’alertes, trop de rapports proches, trop de patchs à qualifier, et une capacité de triage qui devient le vrai goulot d’étranglement.
Que doivent faire les exploitants d’infrastructure ?
Ils doivent renforcer l’inventaire, la veille CVE, la priorisation, les fenêtres de maintenance, les mitigations temporaires, les tests post-patch et la capacité à appliquer des remédiations plus fréquentes.
Articles recommandés
Intelligence Artificielle
Claude Code, ChatGPT Codex: guide de démarrage
Comment démarrer proprement avec Claude Code ou ChatGPT Codex: environnement VSCode, WSL, Docker, Git, consignes projet et bonnes pratiques de sécurité.
Sécurité
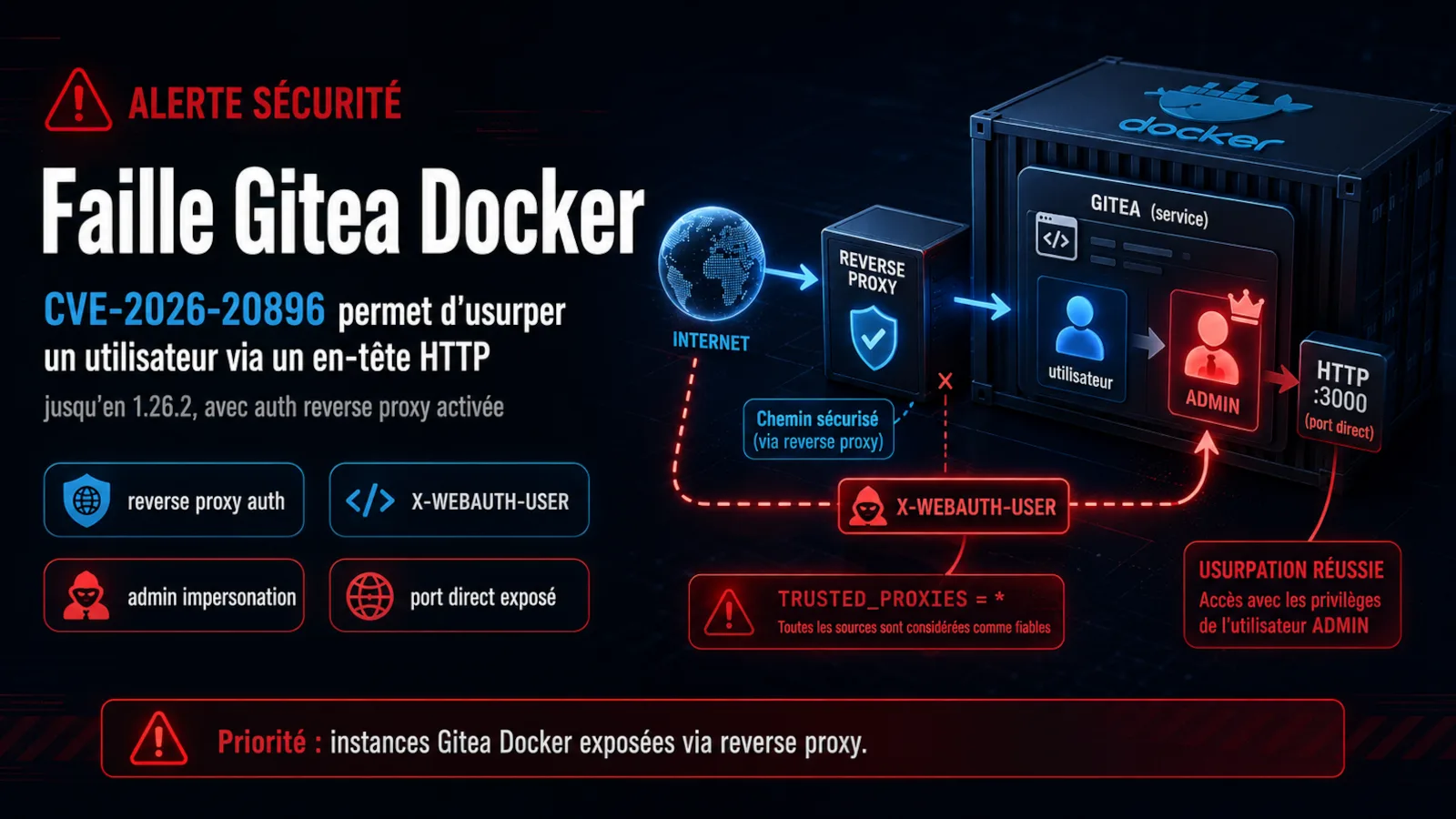
Faille Gitea Docker : CVE-2026-20896 permet d'usurper un utilisateur via un en-tête HTTP
CVE-2026-20896 affecte les images Docker officielles de Gitea jusqu'en 1.26.2. Avec l'authentification reverse proxy activée, un attaquant peut se faire passer pour un utilisateur, y compris administrateur.

Sécurité
GhostLock (CVE-2026-43499): faille Linux locale root et container escape à patcher
GhostLock, suivie sous CVE-2026-43499, est une faille locale du noyau Linux dans rtmutex/futex PI. Elle peut mener à une élévation de privilèges root et à une évasion de conteneur sur noyau vulnérable.